
BitTorrent Enters AI Computing: BTTInferGrid Builds a Decentralized AI Inference Computing Network
- Core Insight: BitTorrent has launched BTTInferGrid, which seeks to aggregate idle global GPU resources in a decentralized manner, providing low-cost, high-elasticity computing services for the high-growth AI inference sector. This addresses the structural challenges of the current centralized computing system, including cost, flexibility, and supply-demand mismatches.
- Key Elements:
- The AI industry has entered the "inference era," with over 70% of computing power expected to be used for inference. ChatGPT's daily inference cost is approximately $700,000, highlighting the exponential growth in demand for inference computing and the immense cost pressure.
- The centralized computing system has three major shortcomings: lack of elasticity leads to an imbalance between cost and stability; GPU rental prices have risen nearly 40% in the past six months, hindering innovation; and a large amount of global idle GPU resources remain unused, resulting in a severe supply-demand mismatch.
- BTTInferGrid's core positioning: Build a decentralized computing network that connects the supply side (idle GPUs) with the demand side (AI developers), offering open access, on-chain verifiable results, and pay-as-you-go services.
- Its three main advantages are: lowering the barrier to entry to rapidly aggregate global computing power; achieving trusted verification through task scheduling and cryptographic spot checks; and adopting a demand-driven economic model, avoiding the common "death spiral" seen in DePIN projects.
- Leveraging BitTorrent's over 100 million active users and its experience with BTFS storage, the platform has a mature operational foundation for DePIN. It will evolve in stages (2026-2028) into an open, foundational AI infrastructure.
 As AI Agents are deployed in various complex scenarios such as enterprise workflows, automated production, and autonomous execution, the global AI industry has officially transitioned from a phase of "passive response" to a new era of "autonomous execution." The core of industry competition is no longer about pitting large model parameters against each other but has shifted towards execution capabilities. Strong logical reasoning abilities are the fundamental foundation supporting this transformation.
As AI Agents are deployed in various complex scenarios such as enterprise workflows, automated production, and autonomous execution, the global AI industry has officially transitioned from a phase of "passive response" to a new era of "autonomous execution." The core of industry competition is no longer about pitting large model parameters against each other but has shifted towards execution capabilities. Strong logical reasoning abilities are the fundamental foundation supporting this transformation.
This paradigm shift in application scenarios has also driven a fundamental change in upstream computing infrastructure demand: the center of gravity of computing power consumption is continuously shifting from model training to business inference, an irreversible trend. However, the current mainstream centralized computing system faces challenges when handling massive, high-frequency inference requests with drastic peak-to-valley fluctuations, exposing issues such as high operational costs, weak elastic scaling, and insufficient service stability. The entire AI industry is encountering a bottleneck in computing power supply.
On June 17, the established decentralized transmission ecosystem BitTorrent launched a strategic product: BTTInferGrid. Targeting the AI inference赛道, it builds a decentralized computing network. Leveraging a decentralized distributed architecture, the platform efficiently aggregates scattered idle GPU computing resources globally, bridges the connection gap between resource suppliers and AI developers, and provides AI inference computing services that are open, easily accessible, with results verifiable on-chain, and flexible pay-per-use billing.
Relying on the advantages of decentralization, BTTInferGrid not only addresses the weaknesses of traditional centralized computing in high-concurrency and load-fluctuation scenarios but also achieves a leapfrog breakthrough in computing supply, restructuring the resource allocation and flow logic of the entire computing ecosystem.
At the same time, BTTInferGrid is a strategic product upgraded from BitTorrent's existing BTFS service. This is not only a key extension of BitTorrent's long-cultivated decentralized resource scheduling capabilities from the storage track to the computing power domain but also a crucial move in its layout of the decentralized AI赛道.
Computing Demand Structure Shifts from "Training" to "Inference": BTTInferGrid Reconstructs AI Inference Computing Supply through Decentralization
BTTInferGrid aims to restructure the computing supply system using a decentralized model, solving issues like high costs and supply shortages for AI inference computing. By reducing costs and improving efficiency while enhancing large model inference performance, it provides the industry with high-performance, resilient, and cost-effective computing infrastructure.
If 2024 to 2025 was the era of the "thousand-model war" and the parameter arms race dominated by ten-thousand-card clusters in the AI industry, then 2026, with the large-scale deployment of AI Agents, marks the official entry into the "Inference Era" of massive application explosion. AI inference is the key link for realizing model value; it transforms "trained models" into practical applications, commercial value, and everyday services. Simply put, training is "teaching AI to learn," while inference is "letting AI be used in practice"—for example, an autonomous car recognizing a stop sign on a road it has never driven on is a classic inference behavior. Inference capabilities directly determine the user experience, operational costs, and commercial value of AI products.
There is a broad consensus in the industry that over 70% of future computing resources will be used for inference scenarios. Oracle has predicted that the market size for inference computing will eventually surpass that of training computing. Academician Zheng Weimin of the Chinese Academy of Engineering also pointed out that the vast majority of current computing power is consumed in daily interactions between users and large models. Looking at cost composition, human labor accounts for only 3% of large model inference expenses, data accounts for 2%, while computing power accounts for a staggering 95%. The inference costs for leading applications are substantial: ChatGPT's daily inference cost is approximately $700,000, and DeepSeek V3 reaches $87,000.
When AI computing demand shifts from the centralized training of a few tech giants to the commercial inference scenarios of millions of developers across various industries, the criteria for evaluating underlying infrastructure also change. In the training era, developers mainly focused on the centralized scale and efficiency of computing power. Entering the inference era, AI services directly face massive end-users, with hundreds of billions of daily interactions generating enormous computing consumption. Developers' attention has shifted to the cost per call, response speed, and service stability. Now, computing supply, call costs, and service availability have become the core benchmarks for evaluating AI infrastructure and the key factors determining whether AI applications can be successfully deployed.
However, facing exponentially rising inference demands, the weaknesses of the mainstream centralized computing system are becoming increasingly apparent: continuously rising GPU rental prices, frequent platform service outages, and many AI applications being forced to shut down due to computing costs. These issues are mainly concentrated in the following three aspects:
First, insufficient computing scheduling elasticity, inability to handle traffic peaks and valleys, leading to an imbalance between cost and stability: Although leading AI companies and cloud providers continue to increase investment in computing facilities, inference demand grows rapidly and exhibits clear peak-and-valley characteristics—requests can surge dozens of times during daytime office or marketing peaks, only to plummet sharply late at night. Centralized data centers lack the elastic scheduling ability to adapt to this dynamic change: configuring for peak loads results in high depreciation costs during low periods; configuring for average loads leads to service interruptions during peak periods, creating a dilemma between "high cost" and "low stability." Furthermore, centralized computing incurs multiple layers of costs, including data center construction, electricity, operations and maintenance, and commercial profit margins, ultimately making computing costs prohibitively high, significantly squeezing the error-correction space for small and medium-sized innovative teams. The market urgently needs new solutions that combine cost advantages with elastic scheduling capabilities.
Second, GPU rental prices are rising continuously, with high costs hindering innovation and deployment by SMEs and developers: Although open-source large models (like Qwen, DeepSeek, etc.) have lowered the entry barrier for the AI field, model deployment and operation still rely on stable, cheap, and easily accessible inference computing power. However, the reality is that GPU rental fees are constantly increasing. Taking the mainstream H100 graphics card as an example, its hourly rental price rose from $1.70 in October 2025 to $2.35 in March 2026, an increase of nearly 40% in six months. The high cost deters many individual developers and SMEs with excellent solutions, trapping them in a situation of "having models but no computing power," severely stifling innovation vitality and large-scale development in the AI industry.
Third, a large amount of idle global GPU resources remains underutilized, resulting in a severe supply-demand mismatch: In stark contrast to the market's "computing power famine," a vast volume of idle high-performance GPU computing resources is scattered globally across personal devices, university labs, small data centers, and facilities left over from the cryptocurrency transition. Due to the lack of standardized access channels and efficient scheduling engines, this computing power cannot enter the mainstream inference market, creating a contradictory situation where demand faces "difficulty finding cards" while supply experiences "computing power dormancy." There is enormous potential for improving resource utilization, and this supply-demand mismatch urgently needs to be resolved.
In summary, the current AI inference computing market is facing a triple structural dilemma: centralized supply cannot balance cost and elasticity, escalating computing rents suppress AI innovation, and vast amounts of idle GPU resources remain dormant and unactivated. Faced with these industry challenges, BTTInferGrid leverages decentralized technology to offer a new solution for cracking the supply-demand mismatch in computing.
BTTInferGrid aims to efficiently connect globally dispersed idle GPU resources with a massive number of AI developers through a decentralized approach, fundamentally breaking the monopoly and bottleneck of centralized computing. On one hand, the platform integrates scattered idle GPU computing power to build an open and shared computing infrastructure. On the other hand, it opens up the connection channel between supply and demand, eliminating the access barriers and pricing black boxes of traditional centralized models. At the same time, relying on the incentive and coordination mechanisms of DePIN, BTTInferGrid can continuously deliver cost-effective inference computing power, fundamentally resolving the core pain points of high computing costs and supply shortages, truly unleashing the inference efficiency and commercial value of large models.
BTTInferGrid: Building a Decentralized Computing Network for AI Inference, Three Major Advantages Redefine Computing Allocation Mechanisms
BTTInferGrid has a clear and specific positioning: dedicated to building a decentralized computing network for AI inference scenarios, connecting global idle GPU computing supply with AI inference market demand, and providing a global AI computing service system that is open for access, results-verifiable, and pay-per-use.
Specifically, BTTInferGrid relies on the underlying DePIN network mechanism to precisely match computing supply with the explosive growth in AI inference demand, achieving bidirectional value empowerment for both supply and demand:
· Computing Supply Side: Efficiently aggregating fragmented idle GPU resources globally to build an open and shared computing base. By leveraging DePIN's incentive and intelligent scheduling mechanisms, it creates a low-barrier, sustainable revenue channel for computing power holders, turning globally idle "sleeping GPUs" into truly "liquid assets." Meanwhile, it ensures computing stability and elastic scaling, building cost-effective, highly scalable, secure, and reliable global inference service capabilities.
· Computing Demand Side: Providing global AI developers with easy-to-access, on-chain verifiable, pay-per-use global inference services. Compared to the high premium pricing of centralized cloud providers, BTTInferGrid offers extreme cost advantages and elastic scaling capabilities, helping small and medium-sized tech teams and independent developers reduce business trial-and-error costs, efficiently complete product validation and business iteration, while also empowering the upstream computing supply ecosystem.
Thus, BTTInferGrid not only effectively addresses AI developers' urgent need for low-cost, highly elastic computing power in the fiercely competitive "application deployment" phase but also opens a sustainable value monetization channel for the vast amount of idle hardware resources worldwide.
More importantly, the BTTInferGrid platform will successfully build a self-sustaining positive growth flywheel: idle GPU nodes continuously expand, inference computing costs keep decreasing, attracting more developers; market demand continues to rise, further incentivizing global computing suppliers to join the ecosystem. BTTInferGrid uses a decentralized model to reconstruct computing supply, transforming scarce, high-priced dedicated AI computing power into inclusive, on-demand AI public underlying infrastructure.
In terms of product performance advantages, most current decentralized GPU platforms on the market commonly suffer from issues like high barriers to computing access, insufficient service trustworthiness, and unsustainable economic models. BTTInferGrid, however, optimizes from the underlying architecture, achieving comprehensive breakthroughs in three dimensions: computing aggregation, service verification, and economic sustainability, forming a unique core competitiveness. The specific advantages are as follows:
1. Open Access Computing Supply Network, Rapidly Aggregating Global Idle GPU Resources: Traditional cloud computing has high entry barriers (requiring compliant data centers, fixed public IPs, expensive switches, etc.). BTTInferGrid builds a truly open access computing supply network where any entity or individual with idle GPU or other computing resources can seamlessly connect, provided they meet basic performance parameters (like VRAM capacity, computing benchmark) and network stability requirements. This design significantly lowers the participation threshold on the computing supply side, enabling global idle GPU computing power to be aggregated into a network matrix at a very high speed.
2. Verifiable Service Quality and Node Behavior, Solving the Decentralized Trust Problem: The biggest pain point of decentralized computing is trustworthiness—how to prevent miners from using low-end GPUs to impersonate high-performance cards? How to ensure inference results are authentic and reliable? BTTInferGrid builds a cross-verifiable closed-loop through task scheduling (intelligent distribution), challenge verification (cryptographic spot checks), consensus scoring (dynamic reputation score), and on-chain coordination (smart contract rewards and penalties), effectively enhancing the trustworthiness of inference services.
3. Demand-Driven Economic Model, Building a Sustainable Ecosystem: Early DePIN projects often fell into a death spiral of "high token issuance attracting nodes for blind mining, but lacking real demand, leading to token inflation, price crashes, and node departure." BTTInferGrid established from its inception the goal of creating an economic ecosystem driven by real demand—using real inference calls and node performance as the core incentive basis. Only when AI developers genuinely pay to call models can computing providers earn core revenue shares and reputation bonuses. This design will effectively promote the healthy and adaptive growth of supply scale and market demand, ensuring the long-term healthy and sustainable development of the network ecosystem.
In summary, from breaking traditional access barriers with an open supply grid allowing any globally compliant idle GPU to connect seamlessly, to a full-process verifiable trust defense built on a four-fold closed-loop of task scheduling, challenge verification, consensus scoring, and on-chain rewards and penalties, to finally eliminating speculative bubbles and anchoring incentives to real AI inference calls within a demand-driven economic model—BTTInferGrid is redefining the allocation mechanism of computing resources from the three dimensions of resource aggregation, service trustworthiness, and value distribution.
BTTInferGrid Will Build a New Computing Ecosystem Driven by Real Demand in Phases
BTTInferGrid is not a simple "computing aggregator" but a sophisticated decentralized computing network integrating multiple functions, including AI inference task scheduling and execution, intelligent matching and connection of computing supply and demand, and on-chain resource coordination and settlement.
Within the BTTInferGrid decentralized computing ecosystem, all participants form three core roles around the "supply, use, and verification" of computing power:
· Computing Supplier (Miners): Provide idle GPU resources, accept and execute AI inference tasks. The system automatically distributes corresponding rewards based on the verified actual workload, task completion quality, and dynamic performance scores.
· Computing Demander (AI Developers): BTTInferGrid provides standardized and unified API service interfaces, supporting developers in accessing globally distributed GPU resources.
· Network Guardians (Validators): Participate in the decentralized verification and scoring system, auditing and randomly challenging the computing performance of miner nodes, identifying anomalous behavior, and maintaining network service quality. Meanwhile, validators receive rewards for maintaining network integrity, collectively ensuring the fairness and trustworthiness of the network.
In summary, for AI developers, BTTInferGrid brings more cost-effective, highly scalable, secure, and trustworthy AI inference services, effectively alleviating product interruptions and customer churn caused by insufficient computing power. For GPU providers, it activates global edge and idle hardware resources, establishing a sustainable revenue channel for GPU resource providers, allowing every unit of computing power to realize its value in the inference era.
Regarding specific product deployment, unlike the asset-heavy model of traditional centralized cloud providers that "stack hardware first, wait for demand later," DePIN naturally faces a two-sided coordination challenge in its early construction phase—oversupply leads to idle nodes and token economy collapse, while undersupply harms developer experience and system efficiency. To this end, BTTInferGrid has formulated a clear, robust, and demand-oriented phased launch strategy, abandoning disordered and extensive growth and prioritizing resource utilization, economic sustainability, and the steady expansion of the technical architecture.
· Short-term Goals (2026): Network cold start, completing the connection of core underlying nodes and distributed inference service verification, gradually expanding the scale of GPU nodes.
· Medium-term Goals (2027): Ecosystem diversification, improving network service stability and privacy security, while simultaneously supporting more AI model formats and inference frameworks, gradually extending to application scenarios like model fine-tuning.
· Long-term Goals (2028 and beyond): Becoming AI-native underlying infrastructure, building the preferred computing layer for AI Agents and automated applications, providing elastic computing support for large-scale AI applications, ultimately enabling computing power, distributed storage, and on-chain smart contracts to operate synergistically within a unified architecture.
In terms of execution, BTTInferGrid also adopts a phased evolution strategy. In the initial launch phase, the network primarily uses professional-grade GPUs, computing suppliers (miners) need to pass an audit for access, and demand-side users can call inference services through the platform. In the future, it will evolve into a fully open super computing grid: supporting various GPU types including consumer-grade, professional-grade, and data center-grade, with performance-based tiered access and pricing; open access for miners, while introducing a staking mechanism to ensure service quality; providing a unified API interface on the demand side, compatible with multiple AI model formats and inference frameworks, offering flexible deployment options.
Currently, BTTInferGrid has successfully integrated several mainstream open-source AI large models, including Alibaba Cloud Qwen Series Qwen3.6 27B and Qwen2.5 7B Instruct, as well as Meta's Llama 3.1 8B Instruct. AI developers can flexibly call models on demand based on their actual business scenarios. In the future, the platform will continue to expand its model ecosystem, providing developers with support for more cutting-edge models.
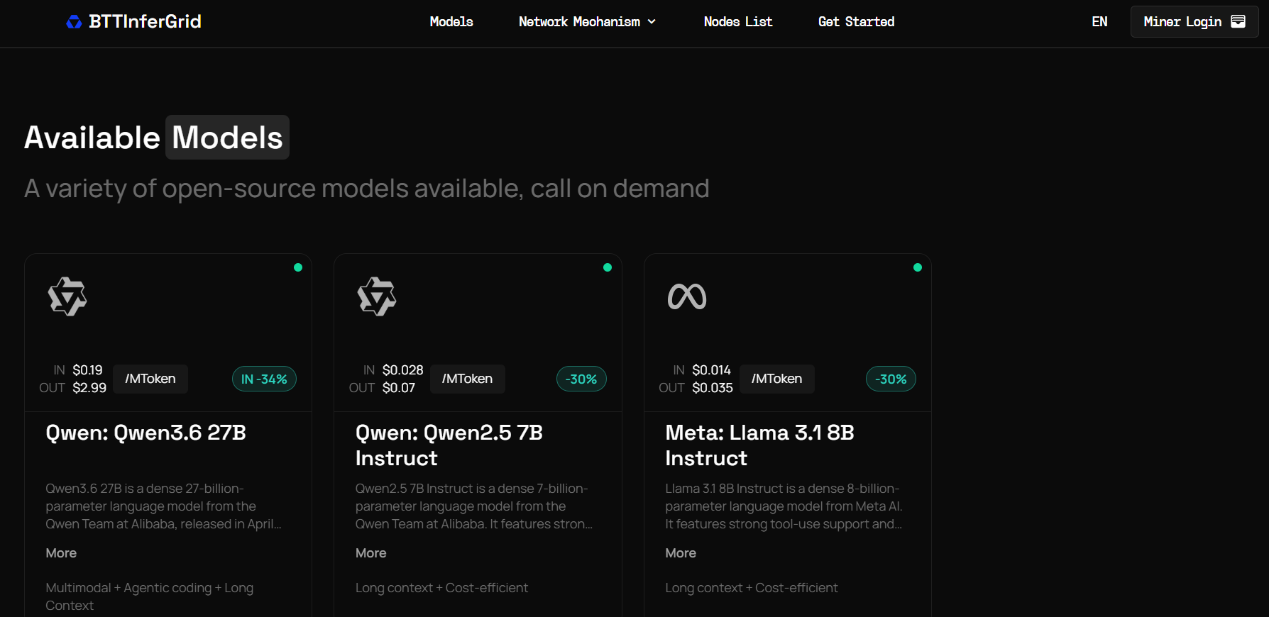
More importantly, BTTInferGrid has the solid backing of BitTorrent's and BTFS's long-term accumulation, giving it inherent development advantages. BitTorrent and its subsidiary BTFS have深耕d the decentralized storage field for years. BitTorrent itself boasts over 100 million active users and 2 billion installations, having successfully validated the feasibility of the DePIN model and accumulated mature capabilities in resource access, token incentives, on-chain settlement


